Tuesday, June 18, 2013
Auto-generated 3D Models - Appendix B

Meet The BIG-3D-GENERATOR Machine
An automatic machine to create a 3D model of the whole world from aerial shots...
One of the oldest dreams of mankind is taking place - isn't it?
In this appendix we'll define this intriguing machine, and begin to examine some of its interesting features and practical implementations and applications.
AUTO-GENERATED 3D MODELS
APPENDIX B
THE BIG-3D-GENERATOR MACHINE
© Enrico Dalbosco (Arrigo Silva) April-June 2013
Last update: June 18, 2013
Index of contents
PART 1 - ENVIRONMENT
PART 2 - A VISUAL CONFRONTATION
PART 3 - CEZANNE'S LESSON
PART 4 - [... work in process ...]
Appendix A - ABOUT ST. JOHN AUTO-GENERATED
Appendix B - THE BIG-3D-GENERATOR MACHINE <== Current Post
Appendix C - Our Old Models Now Very Slim
APPENDIX B - THE BIG-3D-GENERATOR MACHINE
Introduction [boring but to read...]
This appendix presents two aspects: a seemingly theoretical aspect, namely the definitions of the generating machines of the series B3G, and a noticeably much more practical aspect, namely the identification of the potentialities and limitations of these machines - and consequently of the auto-generated models.
I have no particular specific titles in the theoretical field on 3D modeling (I am an electronics engineer, I have worked in the computer field, and I am just a curious person who tries to keep informed on the progress of science) and then I don't pretend to spread "The Scientific Word" about Stereoscopy, Photogrammetry, Computer Science or whatever... Consequently I invite you to take what you read with a pinch of salt - and to help me to overcome any errors or inaccuracies that may appear in this paper.
But I have from my side long weeks - maybe months - passed in designing 3D models, in examining and choosing dozens (hundreds) of photographs, in identifying geometries and handling textures, in trying to build the correct interfaces with the Google Earth terrain... and then I think I can understand and imagine what should get, have, know, do, etc. an automatic machine generating 3D models on the basis of more or less aerial photographs - and of course consujlting a number of documents about these topics I could found on the web.
So I hope that this brief dissertation does not bother you, but can in fact be useful to objectively define what can do the machines and what they can NOT do but can do we, passionate builders of 3D models.
This appendix presents two aspects: a seemingly theoretical aspect, namely the definitions of the generating machines of the series B3G, and a noticeably much more practical aspect, namely the identification of the potentialities and limitations of these machines - and consequently of the auto-generated models.
I have no particular specific titles in the theoretical field on 3D modeling (I am an electronics engineer, I have worked in the computer field, and I am just a curious person who tries to keep informed on the progress of science) and then I don't pretend to spread "The Scientific Word" about Stereoscopy, Photogrammetry, Computer Science or whatever... Consequently I invite you to take what you read with a pinch of salt - and to help me to overcome any errors or inaccuracies that may appear in this paper.
But I have from my side long weeks - maybe months - passed in designing 3D models, in examining and choosing dozens (hundreds) of photographs, in identifying geometries and handling textures, in trying to build the correct interfaces with the Google Earth terrain... and then I think I can understand and imagine what should get, have, know, do, etc. an automatic machine generating 3D models on the basis of more or less aerial photographs - and of course consujlting a number of documents about these topics I could found on the web.
So I hope that this brief dissertation does not bother you, but can in fact be useful to objectively define what can do the machines and what they can NOT do but can do we, passionate builders of 3D models.
References
- Stereoscopy
- The Basics of Photogrammetry
- The Light Fantastic - Using airborne lidar in archaeological survey (2010)
- How to Work with LiDAR Point Clouds in AutoCAD Map 3D
- Automated reconstruction of walls from airborne LiDAR data for complete 3d building modelling
- aero3dpro.com.au Video Gallery
- HR 3D models of North Adelaide in Google Earth - aero3Dpro
- The Basics of Photogrammetry
- The Light Fantastic - Using airborne lidar in archaeological survey (2010)
- How to Work with LiDAR Point Clouds in AutoCAD Map 3D
- Automated reconstruction of walls from airborne LiDAR data for complete 3d building modelling
- aero3dpro.com.au Video Gallery
- HR 3D models of North Adelaide in Google Earth - aero3Dpro
B1. YESTERDAY - THE STEREOSCOPIC REPRESENTATION
The dream of recreating the world (or at least a partial view of the world) to all-round is as old as humanity. Not satisfied with the possibilities offered by the sculpture and the perspective drawing, in the 1830s sir Charles Wheatstone (Gloucester 1802 - Paris 1875) invented the Stereoscopy, a technique that allows us to see a three-dimensional scene observing two slightly different images on a simple device that convey each image to the proper eye.
At first Stereoscopy used two drawn images, but towards the end of the [nineteenth] century, given the enormous progress of photography, the stereoscopic images were produced with cameras, and this technique was perfected to the point that Kodak built and marketed a special camera with two lenses, which guaranteed the right distance of the two views and the simultaneity of the shots.
The following figure shows how at the beginning of 1900 a man could have taken from space a "three-dimensional photograph" using the wonder "Box Brownie" (always because he could ride a space rocket, perhaps of those foretold by Jules Verne, Nantes 1828, Amiens 1905 ;) and then re-view and share with relatives and friends the same perfectly realistc three-dimensional scene through the simple Holmes's viewer.

The figure shows that, already in the early 1900s, using the best available technologies (Quality Setting knob set to a high value) the final result could have been very realistic, as long as they had shot sharp and coherent photographs, taken by appropriate points of view and at the same time.
But what now concerns us most is to observe the relative simplicity of that technology, and to reflect on the quality level of the entire process and then the 3D representation so obtained.
SIMPLICITY - You have to take two photographs at a proper distance from each other - the only caveat is that the object to be represented does not move between one shot and the other. It's for this reason that the machine Kodak is really useful because it ensures (in addition to right distance between the lenses) also the absolute simultaneity of the two shots.
QUALITY LEVEL - The process is very simple and straightforward: you take two photographs, develop them, put themselves in the viewer and look them. The quality depends mainly on the quality of the two photographs, and that is the quality of the celluloid, of the camera lenses, of the development and press, and finally of the lens (if any) of the viewer. All these factors are individually upgradeable in order to improve the quality of the result, that will depend (as is typical in these cases) from the weakest link in the chain.
The quality of these representations may today be considered very high and such as to return a vision almost identical to reality - and in any case intended to further sure improvements.
B2. TODAY - THE BIG-3D-GEN MACHINE
It's been about a century after the invention of stereoscopy, and inventions, discoveries technological improvements etc. have succeeded - in increasingly frantic manner.
After the old cameras were invented other more sophisticated instruments to capture the various aspects of the world and the universe: radar, radio telescopes, sonar, laser applications, etc.. On the other hand 3D tools are available that allow to build virtual 3D models, to store, distribute and display them not only on personal computers but on a large number of devices and platforms. They have also made important studies, and developed o build automatically (or semi-automatically) 3D models of small objects of centimeters and large objects such as statues, buildings, mountains etc.
The time seems ripe to then allow us to define an Abstract Machine which we will name
B3G = BIG-3D-MODELS-AUTOMATIC-GENERATOR
that lets us automatically create 3D Models from a digital input that contains all the information necessary for a realistic representation of the world.At first we will define an Abstract B3G Machine assuming that it can perform any reasonable operation in accordance with today's advanced technologies, identifying its main characteristics and examining what kind of results it can produce.
In a second step, of course, we will also be concerned with Real B3G Machines today effectively running, trying to identify their features and especially what results they can produce.
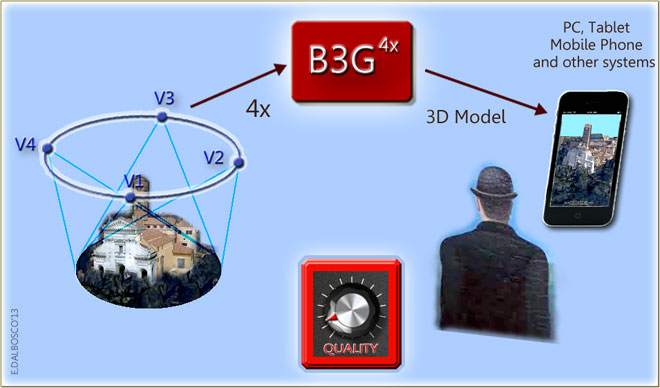
The following illustration shows the machine B3G contest, highlighting the close analogies with those of the Stereoscopy of YESTERDAY - of course this is an evocative image, which is not to be taken literally (in the following we'll provide additional details.
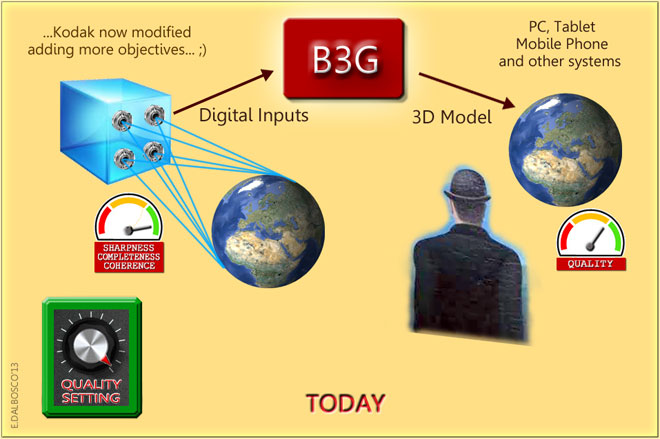
This figure shows the similarities with the Stereoscopy of "YESTERDAY", although the whole process is more and more complex and requires deeper transformations on input data to get the final result.
Here it must immediately report the main difference between our B3G and the stereoscopic machine of YESTERDAY, namely:
the old stereoscopic machine fixed a "specific scene"
(only one view of the reality choosen between the infinite possible views)
so we can review it only from those point of view
exactly "as it is" so we can review it from all possible points of view
(only one view of the reality choosen between the infinite possible views)
so we can review it only from those point of view
WHILE
the new B3G Machine aspires to capture a whole "block of reality"exactly "as it is" so we can review it from all possible points of view
It is evident that the B3G Machines will have different characteristics depending on the size and characteristics of the models to reproduce - from Axial Tomography to reproduction of small object such as vases or artifacts, from manufacturing applications to the reproduction of entire buildings, monuments, cities and nations - as intend to do some distributors of services such as Google.
B3. B3G* MACHINE - A GENERAL PURPOSE MACHINE FOR GOOGLE-EARTH
But now let us restrict our investigation to the machines that generate 3D models for Google Earth from georeferenced photographs, and define the B3G* Machine.
We define the B3G* Machine
as a machine that generates automatically 3D Models
for Google Earth on the basis of georeferenced
digital inputs taken from a number of points of view.
as a machine that generates automatically 3D Models
for Google Earth on the basis of georeferenced
digital inputs taken from a number of points of view.
Let us now provide a slightly more formal a diagram of the context in which the B3G* Machine operates.
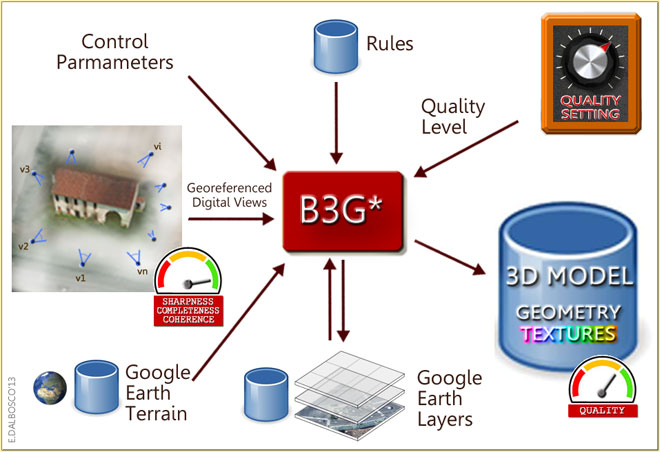
The diagram shows the context in which the B3G* works (the asterisc indicates the "general purpose" machine)
The model of Roman Grating old farm-house was realized by Arrigo Silva, June 2008.
And here's a brief description of the B3G* Machine:
- the purpose of the 3DG* machine is to produce a 3D model of the portion of the world (or "block of reality") localized in a position specified in Control Parameters
- B3G* can accept as input Georeferenced Digital Views of the "block of reality" to reproduce (they can be photos taken from various points of view or 3D Maps or other digital inputs)
- in the placement of the models B3G* takes into account the information relating to the altimetry (Google Earth Terrain database) and to other models or information already stored in the Google Earth Layers database
- B3G* operates on the basis of instructions, rules and algorithms stored in the Rules database
- among the many parameters that control the automatic creation of the models, particularly importance is the Quality Level, which determines (inter alia) the degree of precision of the 3D model to be produced
- the 3D Models auto-generated are made available as 3D objects and are placed in the appropriate level of the Google Earth Layers
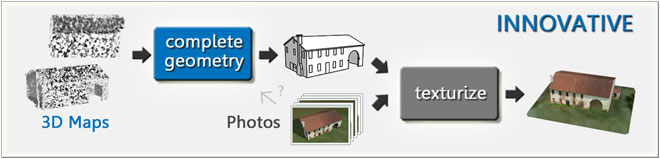
Particularly important in the working process are the two steps schematized in the following schema (THE PROCESS CORE) and that is the step define geometry wich provides for the creation of the geometric structure of the 3D model (edges and faces, for instance) and the later step texturize in which this structure is coated with the appropriate textures.
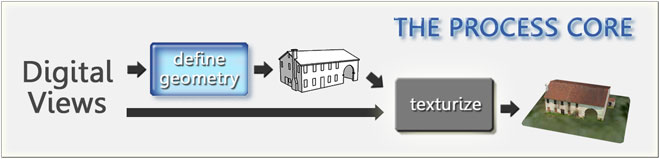
Of course the description that I have provided so far may seem rudimentary, but nonetheless it is enough to give us an idea, as well of the B3G* Marchine complexity, also of its main features in order to better sketch and explain its potentialities and its limits.
THE QUALITY OF THE RESULTS
As in any system, and thus for our B3G* Machine, the rule is that the quality of the final result depends on the quality of the various steps of the tranformation process but also, of course, on the quality of the input information (according to the ancient GIGO law ;)
Since B3G* Machine is proposed ambitiously to reproduce the whole world, capturing and processing (not only "one-off" but perhaps periodically) a wealth of information to produce a result original and unpublished on such a vast scale, it is logical to expect that the most modern technologies are heavily involved in this enterprise, and that the right choice can be decisive for the success of the operation in terms of cost, time and quality.
Therefore it seems to me important to make a mention of the most significant technological approaches that should be used for the provision of the appropriate digital inputs and to ensure efficiency and efficacy in the transformation ensuring the right quality of the results.
Put in a nutshell, as I understand the methods practiced today can be divided into two main categories:
A) methods using the traditional approach based on georeferenced photos
B) methods using an innovative approach based on 3D MAPS (of LiDAR type) and georeferenced photos
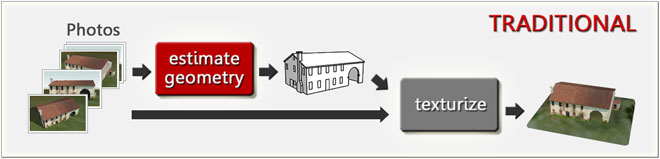
A) THE TRADITIONAL APPROACH
This approach uses the photos (georeferenced isometric views and/or other georeferenced views) just to accomplish the most complex transformation of the whole process: identifying and derive the geometry of the objects. The algorithm is based on techniques and methods of Photogrammetry, and plans to seek the likely edges of the objects searching for the discontinuities present in the various photographs, and thus strengthening the true edges and then the faces, bringing to define the complete geometry of the 3D Model (see the first step estimate geometry in the figure below).
The same, or other, photographs are then used to texturize the 3D Model.
B) THE INNOVATIVE APPROACH
With this innovative approach, however, we have available, in addition to regular photographs, also 3D Georeferenced Maps already done and sure, provided as a "points cloud" (such those obtained with the LiDAR technology, as we can see later). The first step (see the figure below) shall "simply" join and combine the nearby and perfectly integrable maps to get all the points of an object and then convert the resulting "points clouds" into edges and faces without having to consider any photographs - and so bringing to define the complete geometry of the 3D Model. The standard photographs are used only in the second step that provides to texturize the 3D Model.
The LiDAR technology (Light Detecting And Ranging)
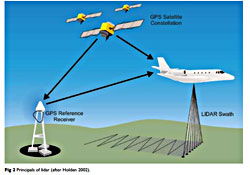 Unlike the conventional camera, which passively records the light coming from the outside world, the method LiDAR plans to send a light impulse to "a number of points" of the outside world and to record, for each point, the time taken by impulse to go back. Since the sender of the impulse can know exactly where it is and the direction in which emitting the impulse, a trigonometric calculation allows to establish the coordinates of the points probed.
Unlike the conventional camera, which passively records the light coming from the outside world, the method LiDAR plans to send a light impulse to "a number of points" of the outside world and to record, for each point, the time taken by impulse to go back. Since the sender of the impulse can know exactly where it is and the direction in which emitting the impulse, a trigonometric calculation allows to establish the coordinates of the points probed.In simple terms, the LiDAR can be compared to a very strong three-dimensional radar that provides a "three-dimensional cloud" of the points probed - incidentally, the LiDAR is not limited to providing the coordinates, but also associates to each point probed interesting and potentially useful information about its nature!
[The picture above, showing the ALS (Airborne Laser Scanning) application that uses the LiDAR technology, is taken from the paper "The Light Fantastic, Using airborne lidar in archaeological survey" - HENGLISH HERITAGE, 2010]
A COMPARISON BETWEEN THE TWO APPROACHES
The two approaches appear complex and very different from each other both in gathering and in processing information, and it is not a simple task to judge which is the best, or the cheapest, or the most accurate: so I will confine myself to make some purely personal and qualitative considerations.
My impression is that the innovative approach appears successful because it is able to obtain a well-defined 3D object (the "cloud of points") directly from reality using sophisticated and precise instruments. Although this object is not completely self-consistent, as it is constituted by a partial view of the piece of reality examined, it however is perfectly integrable with other partial views (ie "points clouds") complementary or partially overlapping.
Another aspect that seems to me the benefit of the innovative approach consists of what in my opinion is the greatest weakness of the traditional approach: namely, that of having to obtain a 3D configuration from a number of photographs taken necessarily from different points of view. To get a result of high quality and reliability, such photographs should be taken simultaneously or at least over a very short time, and in lighting and lights/shadows situation very similar - all conditions often difficult or even impossible to reach, and intended to drive up costs increasing the complexity.
So, with regard to the most delicate phase of the generation of the 3D model, I believe that the innovative approach is able to produce 3D models more reliable and robust, more closely to reality, more detailed and then perfectly integrable with the other 3D models of the surrounding reality.
POSSIBLE WEAKNESS POINTS OF B3G* MACHINE
Precisely by virtue of the fact the B3G* Machine intends to freeze the real world - or at least a "piece of world" - as it appears in a certain "instant" (and precisely in a certain minute of a certain hour of a certain day of a certain month of a certain season of a certain year) it may be subject to some points of weakness.
First, there are clear limits on the timing for then freezing the reality, or the piece of reality, as not all moments are suited to the acquisition of several or numerous views are required to compose a part of the world (eg an entire metropolis) - due to weather conditions, visibility etc.. For the same reason it could be difficult to obtain a consistent 3D representation of a large territory.
One of the biggest problems seems to me to be comprised of the "unstable" objects, ie by moving objects (pedestrians, cars, trucks, etc.) or by objects that evolve more or less quickly (work in progress, renovations, etc.) that introduce [often] bothering elements which [perhaps] can hide most important stable objects (for example significative monuments).
A further problem is caused by vegetation (trees, parks, even considering the large seasonal variations in certain climates), and by objects with very thin or slender structure (poles, fences, fences, etc..), or by very complex objects (monuments, statues, columns, etc.)
B4. AN EXAMPLE OF MODELS AUTOGENERATED IN ROME (JUNE 2013)
In this section I show an auto-generated 3D Model of a "piece of world" present as today in the experimental area of Rome in the new version of Google Maps.
The 3D Model looks just auto-generated by a B3G Machine functioning according to the traditional approach based solely on [four] isometric photographs processed with techniques of Photogrammetry.
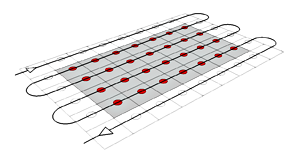 The same machine, that we can call B3G4x, allows you to process an input well standardized (the 4 isometric views) and pick up a photographic campaign aerial patrolling an entire region with a path similar to that shown in the figure on the right.
The same machine, that we can call B3G4x, allows you to process an input well standardized (the 4 isometric views) and pick up a photographic campaign aerial patrolling an entire region with a path similar to that shown in the figure on the right.In my opinion this B3G4x Machine was used to get most of the models [with some... exceptions] in the various experimental areas of Google Maps in the areas of New York, Tokyo, etc.
The next figure shows that the B3G4x Machine at work while generating the 3D Model of the Basilica of Santa Francesca Romana in Rome, using its four isometric views.

Now I'll show you the inputs and outputs of the B3G4x Machine, and precisely:
- the map view of the Basilica (not used by the machine in texturize step)
- the four photos (isometric views) used by the machine to generate the model
- two shots of the Basilica scrren-printed from Google Earth
Then I'll show a few pictures of the auto-generated model and the corresponding hand-made model uploaded in 3D Warehouse and promoted on the photorealistic layer of Google Earth.
The picture below shows a view of the Google Earth terrain with the Basilica:

And now, behold the four isometric views relating to the same area (taken from Bing Maps, since I don't acquire those of Google) though, as you can see, they are not exactly the ones that have been used by B3G - but this small difference does not affect the final result.

And this is the final result as it appeared May 30, 2013:


Of course now it is natural to compare the result of the machine B3G with those obtained from a human modeler of 3D Warehouse. So I've chosen the 3D model of the Basilica "Santa Francesca Romana" created four years ago (June 7, 2009) by our colleague Andrea Pittalis, better known as saikindi - of this model I present below the facade and, in the following, some comparison pictures with the one created by B3G.




It is not my intention here to compare the auto-generated 3D Model with that hand-created by a skilled modeller - I rather think about the quality of the auto-generated 3D Model and wondering if and how its quality, yet rather coarse, can be improved using the same B3G4x Machine old-approach" with a better Quality Level, and what results they can obtain using a B3G3DMaps Machine innovative-approach".
I think that Google, before long, will provide the answers to this and other questions!
B5. EXAMPLES OF AUTO-GENERATED MODELS IN ADELAIDE, AUSTRALIA (JUNE 2013)
I conclude this appendix showing some examples of models (almost certainly) auto-generated.
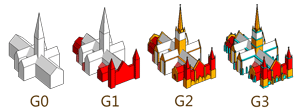 The first image is taken from Google Maps new version, and is the St. Peter's Cathedral in Adelaide (Australia). As you can see its structure looks nice even if you notice some oversimplifications - by applying the Method of classification 3D Models that I have proposed in May 2010 (see illustration on the right), the structure can be classified as G1 with a few detail of G2 - a bit too little, in my opinion, for this interesting Cathedral.
The first image is taken from Google Maps new version, and is the St. Peter's Cathedral in Adelaide (Australia). As you can see its structure looks nice even if you notice some oversimplifications - by applying the Method of classification 3D Models that I have proposed in May 2010 (see illustration on the right), the structure can be classified as G1 with a few detail of G2 - a bit too little, in my opinion, for this interesting Cathedral.
The Cathedral of St. Peter, Adelaide (Australia) from new versione of Google Maps (June 2013)
The next two images (screen-printed) refer to the same Cathedral viewable in the clip provided by aero3Dpro on YouTube, while the last two images (also screen-printed) refer to other views always in Adelaide. These four images, which could be classified as [almost] G3, appear more rich in detail and more refined in buildings, in the vegetation etc.

The Cathedral of St. Peter and other views in Adelaide (Australia)
from HR 3D models of North Adelaide in Google Earth - aero3Dpro
from HR 3D models of North Adelaide in Google Earth - aero3Dpro
END OF APPENDIX B
Do the facts, the pictures and the considerations exposed so far about auto-generated models leave a space (and how big - or small...) to human modelers?

On these and other topics we can treat in the oncoming Part 4.

# posted by Arrigo Silva @ 6/18/2013 06:56:00 PM 

Post a Comment